AI笑话和那些年用过的Agent
各家都不想兼容,软件工程做得稀烂,毁灭吧真的。
AI笑话
老生常谈,openai兼容协议、Anthropic Messages 协议 等等
- 行业霸主OpenAI 兼容协议,特征:最经典的 /v1/chat/completions 格式。
- 新的OpenAI兼容协议:/v1/responses 格式,但供应商较少。
- Anthropic Messages 协议,特征:Claude 家的 /v1/messages 格式。
- Google Gemini 协议,特征:generateContent 与 streamGenerateContent 格式。
- ollama协议,特征:/api/chat 和 /api/generate
全都是野狗,全都别兼容。
codex-cli > 0.80 夹带私有参数 external_web_access
表现,在正确配置 codex.toml 后,仍然报错。
1 | {"error":{"code":"InvalidParameter","message":"The parameter `tool` specified in the request are not valid: `json: unknown field |
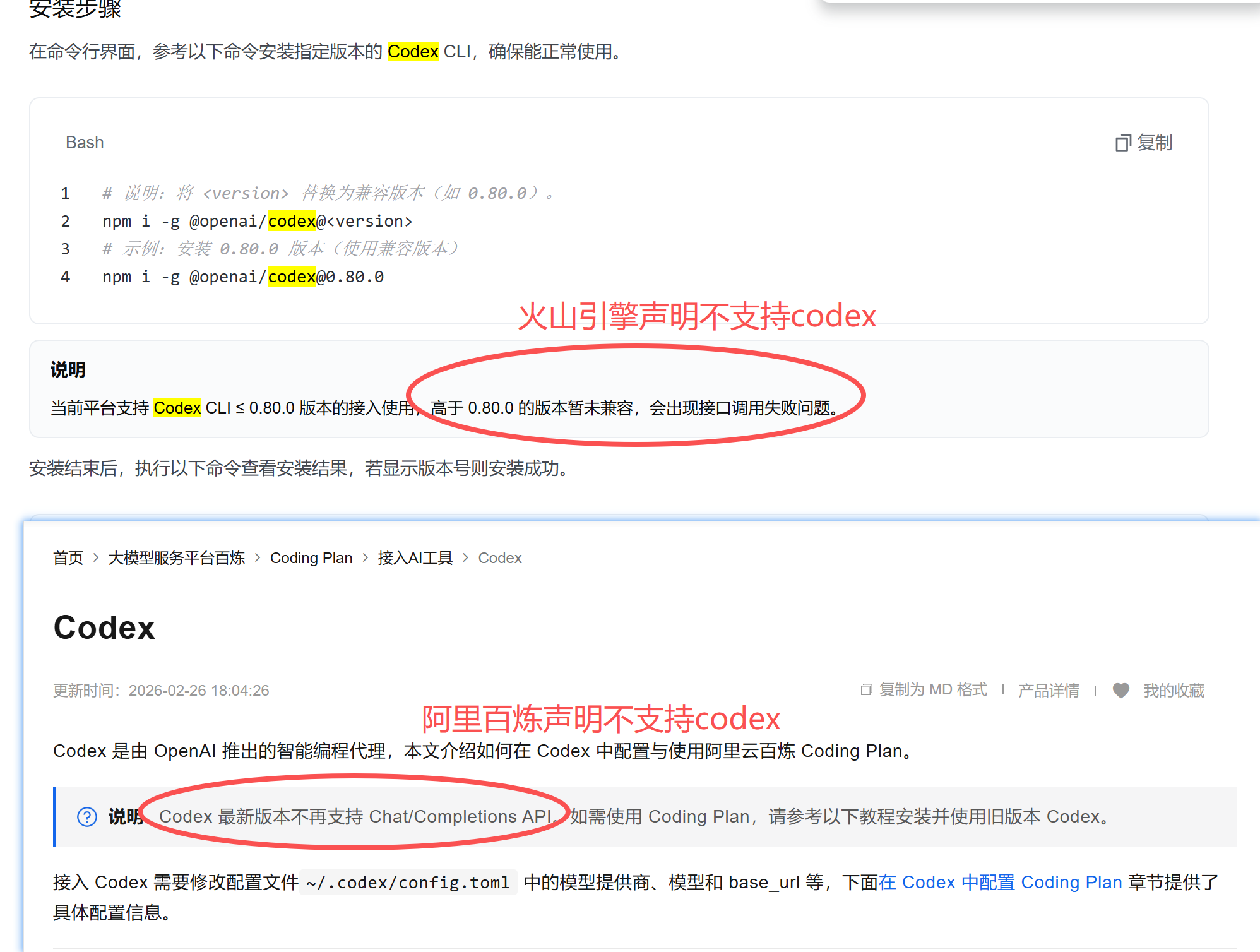
https://github.com/lbjlaq/Antigravity-Manager/issues/1278 external_web_access 字段
结构化输出的大坑、天坑、巨坑、
目前有三种实现结构化输出的方式,一旦用错了,返回的就是胡言乱语:
function_calling (默认方法):这是目前兼容性最广、开发者最常用的模式。它利用了模型供应商提供的“工具调用(Tool Calling)”能力,本质上是曲线救国。
包装:LangChain 将你定义的 Pydantic 模型或 JSON Schema 包装成一个“虚构的函数定义”。
强制调用:在 API 请求中,将此定义放入 tools 参数中,并设置 tool_choice(如 OpenAI 的 tool_choice: { "type": "function", "function": { "name": "..." } })强制模型必须调用该“函数”。
解析:模型不会返回自然语言,而是返回 tool_calls 字段中的 JSON 参数。LangChain 随后使用 PydanticOutputParser 将其实例化。
优点:模型经过专门的微调,对字段提取的准确率极高。
json_mode (基于格式约束):这种方法依赖于模型对输出格式的全局约束,而不模拟函数调用。
参数配置:在 API 请求中设置 response_format: { "type": "json_object" }。
提示词增强:LangChain 会自动检测或要求你的 Prompt 中必须包含 "JSON" 关键字(这是许多模型开启 JSON 模式的硬性要求)。
非强制性:底层模型仅保证输出的是合法的 JSON 字符串,但不保证该 JSON 一定符合你的 Schema 字段定义。
解析逻辑:获取响应字符串后,通过 JsonOutputParser 进行校验和转换。
适用场景:当你需要模型自由发挥,但要求输出必须是 JSON 格式时。
json_schema (严格模式 / Structured Outputs):这是最高级的实现方案,主要对应 OpenAI 近期推出的 Strict Mode 或 Vertex AI 的相关功能。
实现原理:受限采样 (Constrained Sampling):这是最底层的技术差异。在模型生成每一个 Token 时,推理引擎会根据提供的 JSON Schema 实时过滤掉不符合语法规则的 Token。
配置:在请求中设置 strict: true 且 type: "json_schema"。
确定性:这是唯一一种能保证 100% 遵从 Schema 的方法。模型无法拒绝回答,也无法返回 Schema 之外的字段。
局限性:对 Schema 的复杂度有限制(例如不支持某些深层嵌套或特定正则)。
但是啊但是,各模型不一定遵守!不一定支持!
2026年3月测试:
一定要用正规的供应商,一定要用正规的模型!
- 最关键的是看供应商,有的供应商会砍接口、砍功能
- 其次是看模型,有的模型就是不支持某些用法
但正常人很难区分到底是供应商问题还是模型的问题:
- 有的模型,只支持
FunctionCall约束,不支持json_object - 有的模型,只支持
response_format设置为json_object强制输出json,但不保证schema,需要在prompt里写清楚JSON - 有的模型,只支持
json_schema - 有的模型忽略
response_format字段:Claude API Docsresponse_format. Ignored. For JSON output, use Structured Outputs with the native Claude API - 有的模型,提供私有接口,调用私有接口才能获得JSON
因此,根据 prompt 是否需要写清除JSON 格式、使用哪种约束,总共有6种组合,具体你的模型支持哪个组合,那你就猜吧!
因此,我写了一个网页,专门测试,结果见:https://github.com/LeadroyaL/llm-json-hell/issues
rules概念
支持该概念的Agent:.claude、.codex、.cursor,它并非一个广泛的概念,不要老是挂在嘴边。
但是啊但是,这三个里面,有两个的rules表示代码风格约束、有一个的rules表示约束AI执行命令的能力!点名批评OpenAI-Codex!
OpenAI-Codex:https://developers.openai.com/codex/rules/
Use rules to control which commands Codex can run outside the sandbox.
ClaudeCode:https://code.claude.com/docs/zh-CN/memory#organize-rules-with-clauderules
rules/
├── code-style.md # 代码样式指南
├── testing.md # 测试约定
└── security.md # 安全要求
Cursor:https://cursor.com/cn/docs/rules#
使用项目规则可以:固化与你代码库相关的领域知识、自动化项目特定的工作流或模板、统一风格或架构决策
OpenClaw笑话
想吐槽的太多,实在放不下,见 https://leadroyal.cn/p/2605
各个Agent的记忆markdown文件
各玩各的,野狗
| Agent | Memory File | Notes |
|---|---|---|
| Gemini | GEMINI.md | 可配置,支持多个文件和引用。 配置文档 语法文档 |
| Codex | AGENTS.md | 指南 |
| ClaudeCode | CLAUDE.md | 提供自动记忆功能。 文档 |
| Cursor | rules & mdc | 文档 |
| OpenCode | AGENTS.md (优先), CLAUDE.md | 文档 |
那些年用过的Agent
Gemini-CLI
顶级。非常聪明,自从2026年2月,老是服务器繁忙,只能给到顶级。
TRAE-IDE、TRAE-CLI
拉完了。
我是Windows用户,但 trae ide无法区分我在 wsl 里还是 wsl 外,导致在 wsl 里的项目它经常乱执行命令。
trae-cli,支持 豆包、Kimi、Deepseek、GLM,切来切去也无法完成我的编程任务,不确定的 agent 的问题还是模型的问题,感觉是 agent 不行。
OpenCode + GLM
NPC。
毕竟是开源的产品,自带亲和力。
但我用 OpenCode+GLM,仍然无法完成我的编程任务,但体验上比TRAE的强一点,不确定的 agent 的问题还是模型的问题。
在我换成 OpenCode+Gemini后,仍然无法完成我的编程任务。
Codex
人上人。非常聪明,本来支持第三方API,但突然不支持了,吃相难看,只能给到顶级;由于老是在沙箱里断网运行,浪费我大量时间,只能给到人上人。
优点:目前免费额度每周刷新,给得量低强度够用,但高峰期会排队和超时。
缺点:我脚本里需要访问网络,但他老是在沙箱里运行,然后一直排查网络故障和浪费时间,有点笨。
缺点2:因为沙箱里没有网络,我被坑了无数次了,解决方案是 ~/.codex/config.toml
1 | [sandbox_workspace_write] |
Cursor
顶级,用得不多。
缺点:开通会员才允许换第三方API,即便如此,也比 Codex 吃相好多了。
Jetbrain AI
人上人,用得不多。
缺点:也是分不清 wsl,分不清 venv 等虚拟环境。
ClaudeCode
保底顶级,用得不多。
缺点:容易封号。