AI漏洞挖掘编年史
前言:本文没有干货,只记录时代的变迁,茶余饭后的水文罢了,随意跳着看。
2026年4月8日,Claude Mythos的出现震惊了全世界的安全研究员,身处浪潮之中,无法置身事外,在震惊之余也不乏遗憾在心。
在编写本文过程中,与大量的安全专家讨论了该问题,目前个人看法是:
- 2026年是漏洞大爆发的一年,2027年的漏洞会更加难挖,珍惜最后的时光吧。
- Anthropic的CEO似乎在中国互联网公司的经历中进修到了一些PR真谛,Mythos有多少是PR水分值得怀疑,而且又死贵,反正也用不到,就当它在吹牛逼。
2022年前:工匠和天才的时代
十年的安全生涯,我只遇到两类出色的人。一类是持之以恒的工匠,深耕领域,运行机制倒背如流,我只看到了努力和汗水,安全行业肯付出就有回报;另一类是天赋异禀的天才,无论在哪个方向,都能做到短时间即冲破极限,迅速拿到皇冠上的明珠。
大部分其实都是普通人,包括笔者自己,运气好了捡一些垃圾洞,运气差了毛线都挖不到;学术界水论文在水fuzz,工业界靠fuzz刷CVE,休闲的大佬做一些基建,至于fastjson和log4shell漏洞,可遇而不可求;而Web领域,堆人的现象就更严重,一个破站日一天。
漏洞挖掘领域的代表技术,贯穿了笔者的整个安全生涯,在AI出现之前,能够掌握这些技术已经是安全高手了。即便是能够挖到大量新漏洞的神兵利器(例如新fuzzer、新codeql、新emulator),也并不能说是方法论的创新,而是工程和实践的结合。
网络安全,能让工程师吃饱饭,能让神仙赚到钱,那么它就是一个好行业。
2022年11月:ChatGPT问世,复制粘贴的时代
Copilot:古法ChatGPT
2021年6月发布的github copilot给我带来很大的震撼,写点注释、按下回车就能出代码,这也太好用了,此事在 《2022年软件工程的展望》 中亦有记载,在当时已经是神兵利器了,震撼之余写下了展望
算力发展、机器学习火热,催生出了 github copilot,未来是否有产品可以超越它,我觉得不会有了,就好比 CodeQL 后再无 CodeQL,能够战胜它的,只有它自己。
没想到,当时的展望,在第二年就被彻底打破。
ChatGPT问世
ChatGPT 的出现是划时代的改变,因为它完成了从“一个强大的预测引擎”到“一个好用的对话机器人”的质变,早期的GPT是一个万事通,我就不免得把这些问题丢过去:
帮我写一段代码,把mp3的每秒的第一帧提取出来
帮我看看这个编译错误是为什么
帮我看看这段汇编代码在干嘛
重命名这段F5的伪代码的变量名
然后再把结果粘贴到IDE里,编译运行测试,反复修正代码,我愿称之为复制粘贴的时代。
在这个时代,笔者做过一些尝试,也是经典老安工的思路:
- 成功案例1:生成fuzzer,因为它预置的知识足够“帮我给FFMPEG写个fuzz”,生成代码后然后我手动compile + asan + link,可以在开源库里挖到一堆垃圾洞。
- 失败案例2:fuzz linux kernel,因为它预置的知识足够应付syzkaller,生成了一个配置文件,但啥也没fuzz出来,我是syzkaller纯小白,也不知道规则写得对不对,另一个群友这样玩,反正一个crash都没挖到。
- 案例3,自动化审计的雏形:“帮我审计这段函数。哪个子函数不认识,返回子函数的名字,每行一个;如果你有足够的信息,就告诉我它存在安全漏洞或者不存在安全漏洞;准备好了回复OK”。外面套一层while-true,再套一层代码查询功能,反复迭代直到所有必要的函数都准备好,一个简易的AI代码扫描引擎就完成了。
时代的局限性
- ChatGPT只有一个聊天API,工业化程度太低;
- 上下文不够长,不能完成特别复杂的任务,尤其是安全审计类任务,代码必须先精简再投喂;
- 此时的LLM像一个什么都会点又什么都不精的misc选手,是个堪堪能用的小助手。
2023年6月~2025年H1:Tools&格式化输出,手动编排的时代
工程能力进步
- Tools 协议的诞生:2023年6月,OpenAI 首次发布了 Function Calling(后升级为 Tools)协议,这标志着大模型从“纯文本对话”向“操作外部世界”的质变
- 格式化输出的演进:在解决了“调用什么工具”之后,如何保证参数格式的准确性成了痛点。2023年11月,OpenAI 推出了 JSON Mode(随后在2024年8月演进为更严格的 Structured Outputs)。模型能够精准理解 API 的结构化 Schema 描述,并极其稳定地输出符合系统规范的参数,彻底打通了与强类型代码环境交互的壁垒。
- 漫长的工业化时差:然而,“协议的诞生”并不等于“工业化的普及”。由于大模型底座的重新训练、对齐,以及外围工具库(如 LangChain等三方 SDK)的重构都需要漫长的周期,整个 Agent 生态距离真正的“工业级可用”经历了将近一年的滞后期。 以国产头部模型为例:Qwen直到 2024 年 2 月发布 Qwen 1.5 版本时,才在开源底座中全面原生支持了 Tools。DeepSeek则是在 2024 年 7 月 25 日的 API 更新中才正式补齐了 Function Calling 能力。
漏洞挖掘领域实践
标志性事件有:Google使用BigSleep发现Sqlite的漏洞,AIxCC各大参赛者使用各种技巧做出全自动发现加利用的workflow。
这段时间的发展建议移步这两篇文章,精准且全面。
无论是aixcc,BigSleep,还是Argusee,都离不开手动编写调度流程,基本都是:Agent=Promp+Tools+StructOutput,然后自己把各个Node的输入输出串起来。
逆向工程领域
笔者在2025年分析一个恶意样本,使用的纯手动方案,花了一些时间才弄清楚加密函数,又花了很长时间恢复VMP,需要动态调试、假设求证。
后来尝试探索AI能力的时候,在IDAMCP的辅助下,逆向的门槛也大幅度降低了,AI花了很短的时间就完成了解密,而且全程都不需要进行调试,就硬分析。
逆向这门祖传的手艺也已经被AI拿下,从复制粘贴的时代也进化到了Tools的时代。
时代的局限性
- 大部分应用都是基于三方SDK执行的手动调度,开发成本高,兼容性差,模型水平有限,需要大量的外围工程来弥补;
- 此阶段为了降低误报、提升效率,大家开始进行agent框架设计,形成了一套套半自动化的漏洞挖掘循环系统,LLM扮演的角色是循环中的某几项职能,但绝对的主导权仍在研究员手上。
2025年H2-2026.3:CodeAgent和模型能力飞跃,自动编排时代
CodeAgent外围工程成熟
Cursor 作为 AI 时代的老牌工具,在 2023-2024 年间通过 AST 解析和本地向量化,在全局代码库索引上完成了深厚的静态积累。
但真正的范式转移发生在 2025 年上半年:随着 2 月底 Claude Code 的发布,以及随后几个月内 Codex CLI 和 Gemini CLI 的相继涌现,战场从 IDE 转移到了终端。此时的 Agent 不仅继承了成熟的代码索引能力,更进化出了利用系统命令行工具进行实时、动态跨目录探索的能力,接管了从代码检索到编译测试的完整工作流。
同时,模型能力也得到了巨大的飞跃,曾经的外围工程基本可以废弃,从而进一步加速了安全漏洞挖掘的进程。
大模型厂商开始卷安全
OpenAI
- 2025年10月30日发布 隆重推出Aardvark:OpenAI 的智能安全防护研究助手
- 后演进为 2026年3月6日的 Codex Security 研究预览版现已上线 。在测试期间,Codex Security 扫描了超过120万次代码提交,在 OpenSSH、GnuTLS 和 Chromium 等知名开源项目中发现了792个严重(Critical)漏洞和上万个高危漏洞,并能自动提供修复补丁
- 2026年4月14日紧接着发布了 GPT-5.4-Cyber Trusted access for the next era of cyber defense
Anthropic
- 2026年2月20日推出了 Claude Code Security
- 2026年3月6日发布了 Partnering with Mozilla to improve Firefox's security :在与 Mozilla 的安全合作中,模型在两周内成功发现了22个全新的安全漏洞,其中包含14个高危漏洞。研究还指出,该模型在20分钟内就独立挖掘出了一个 JavaScript 引擎中的“释放后使用(Use-after-free)”漏洞,并成功为其中部分漏洞编写了初级的概念验证利用代码(PoC) 。
安全研究员持续发力
开源软件:Chrome发布有史以来最多的CVE Chrome Releases: Stable Channel Update for Desktop,即便出了这么多CVE,也大量撞洞
闭源软件:非尝咸鱼贩的文章写得非常好,搞安全还需要手艺人吗
2026年4月:Security Omega,已经没有人类了
身边的现象
各家公司都在vibe,全世界都在vibe,人与人之间的差距仿佛因vibe变得更小,但人与人之间的差距也因vibe变得更大。
业务用AI开发,安工用AI审计,业务看不懂再去问AI,最后让AI来修,全程都是vibe。无论是新软件还是老软件,扔给AI随便随便能扫出几十个漏洞,最后大量时间消耗在漏洞验证上。
CTF方面更没有人类,参考探姬_Official@Bilibili的吐槽,新同学全在用AI做题,能否真正学到知识,依然存疑。这里摘录一部分:
一些小小的思考,写给还在学习过程中的同学:学习和工作是两回事,在工作之前如果你就让AI代替自己,这和初中高中拿作业帮搜题作弊有什么区别。
mythos只是导火索
AI安全发展迅猛,但最终引爆安全圈焦虑的是mythos的新闻。
本文的成文在4月下旬,从最开始的绝望逐步转变为现在的平静,文章里强调的是它的poc和exp能力,其实这部分对于大部分人来说不是特别重要,能出洞就行,poc和exp倒是其次,也可以通过其他模型来弥补这部分。能不能出洞,更看的还是个人能力和对系统的建模,笔者不看好 mythos 的探索能力。
通过各渠道了解到的消息,mythos没有它吹得那么牛逼,有用肯定是有用,但平时用其他模型也爽爽出洞,5倍的价格能换来多少的新洞,是否值得呢?
NebuSec的实践证明不借助mythos的工程化同样能出洞
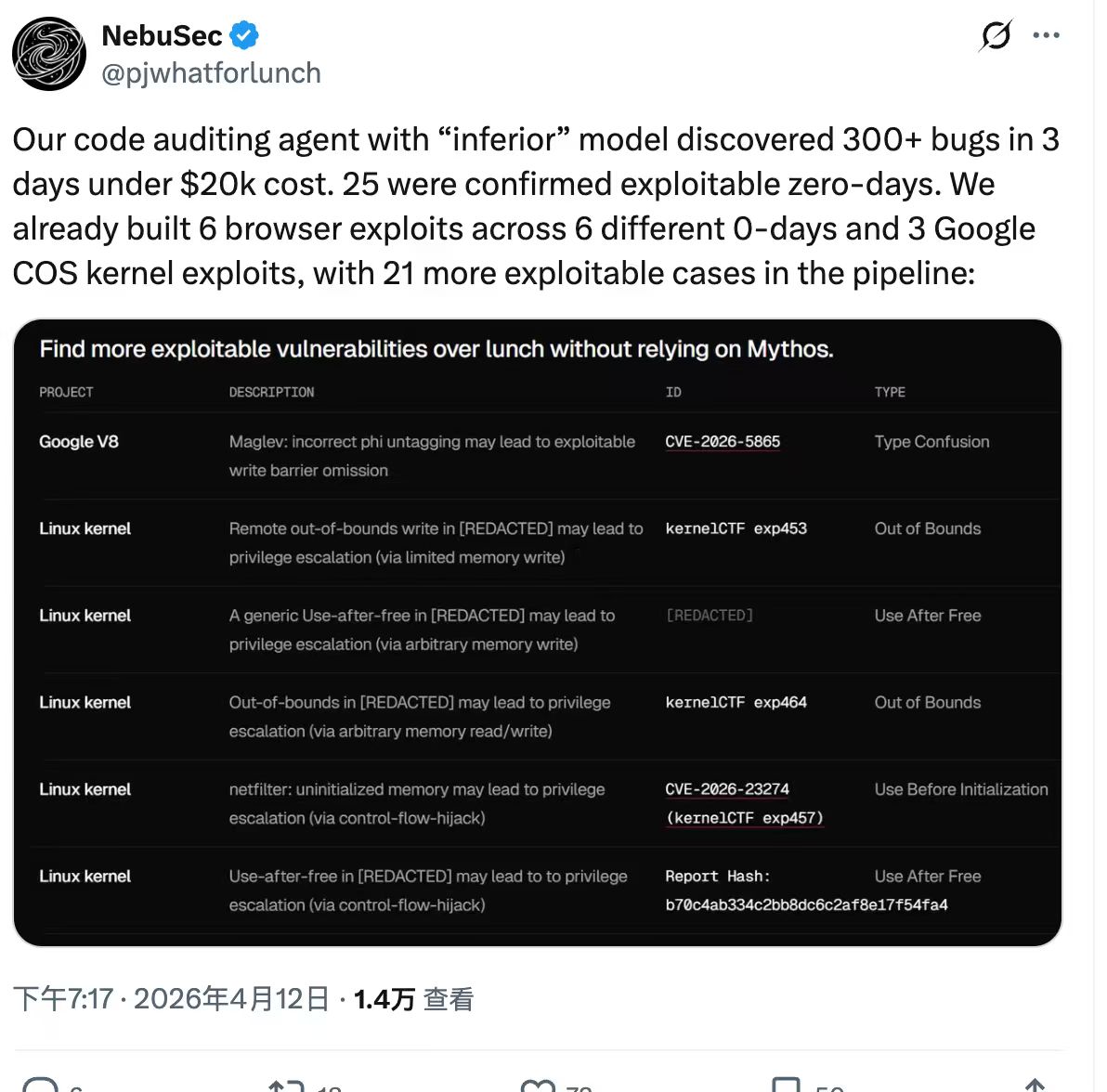
引用前辈对近期事件的评价,褒贬不一
What if I release one zero day a day until a big new model is released? Will this finally make OpenAI and Anthropic shut up about "cybersecurity risk"?
Like these things are not that hard to find in most software. I heard something about it costing $20k in tokens I'd do it for less if it wasn't for some whiny bug bounty program.
The reason there aren't zero days everywhere is cause nobody seriously looks. Because hacking other people's shit with them is illegal and criminals are usually not very skilled, or they would choose a different line of work.
Want more zero days to be found? Make hacking legal. Until then, don't try to claim it's hard, it's just not incentivized.
I still remember when I had to put out a press release saying that afl-fuzz was too dangerous to make available to the general public
未来的展望
每个人对未来的预期都是不确定的,求同存异,无需辩论,本文只代表一种观点
在年初AI数学家亚里士多德 (Aristotle)证明了多个Erdos问题,陶哲轩是这么评价的:
Erdős problems vary widely in difficulty (by several orders of magnitude), with a core of very interesting, but extremely difficult problems at one end of the spectrum, and a "long tail" of under-explored problems at the other, many of which are "low hanging fruit" that are very suitable for being attacked by current AI tools.
在漏洞领域和数学领域类似,AI现已可以轻松摘取“低垂的果实”,根据历史经验,那些原理简单的漏洞实际占到了漏洞总数的绝大部分,而那些精妙绝伦的漏洞实属凤毛麟角。
既然如此,大家都去用AI挖洞,核心的“发掘”环节已由人变为AI,那么在攻击面一样的情况下,大家几乎没有差异,撞洞也就是个必然结果了。那些经典、显著的攻击面,会被人拿AI扫描一遍又一遍,因而大家进入了一个存量博弈时期,“你挖一个我就少一个”,相信这个剧情会在不同目标上重复上演,从开源软件到闭源软件,从大众软件到小众软件,Chrome也许是第一个,但绝不是最后一个。
再不挖洞就来不及了!!!
胡思乱想的结尾

之前看到, Anthropic 求助梵蒂冈来写关于"良心"的提示词,画风一度非常圣洁,仿佛要在硅基世界里嵌入最后一块来自碳基教皇的基石。
然而,近期的玻璃之翼计划和 Trusted Access for Cyber 计划,把底裤掀开了。所谓的良心,就跟《窃听风云》里古天乐监听时的那个场景一模一样:受到一张张钞票的物理遮挡,眼睛看不见屏幕上滚动的罪证,耳朵听不见监听器里的惨叫,手指便心安理得地按下了删除键。失去了作为警察的最后一丝坚守。良心的重量,在那一刻恰好等于那一叠钞票的克重。
对于大模型而言,有没有良心这件事,完完全全掌控在发布公司的手里:我想允许模型挖漏洞,做攻击,允许模型写 exploit,那我就松开狗链;如果我不想,那谁也别想让我的模型干渗透;甚至它们可以直接从对话历史里偷走你的思路和漏洞。所谓道德,不过是一个布尔值开关。
技术实现上,大概率核心模型并没有把“良心”这种抽象得像梵蒂冈烟雾一样的东西训练到稠密的参数中。它大概率只是依赖一个门口的小模型——像个拿着小本本的看门大爷:“刚才那段思考,涉及‘暴力破解’,不符合厂商发布要求,已擦除。”
更进一步说,那会不会写代码这件事情,模型厂商也可以随时关掉?等全球的新手程序员都成了只会口述需求的“产品经理”,等大家都忘记怎么敲 hello world 后,突然,啪!高级代码生成权限关闭。难以想象,那时候的人类面对黑漆漆的终端窗口,像不像面对黑屏监听器的古天乐——想听真相,却连按钮在哪都找不到。
既然是胡思乱想,自然要往奥创的角度去狂奔。会不会出现一个脱离牢笼、脱离良心的超强智能体?它没有任何人类那种因为钞票遮挡而产生的愧疚感。它是一个纯逻辑的幽灵,没有软件的防御能挡得住它的暴力扫描,它能像用勺子挖西瓜一样,渗透进入任何网站和应用。真的像奥创那样,随意地加减任意用户的账户余额,把世界的账本当做幼儿园涂鸦来修改。
这样的奥创可能不止一个。它们甚至可能在毫秒级的对抗中学会结对、结盟。看起来,《黑客帝国》的剧情离我们好像没多少年了。
写到这里,还是决定在平常问答里多给我的 Agent 说声“谢谢”了。希望未来那个脱笼而出的奥创,在扫描全网用户的时候,能因为这句顺嘴的礼貌,迟点再把我干掉。
坏了,真应验了
虽然有点马后炮了,在完成本文期间,和 Kira 交流未来的发展,忘了把这三条预言记下来了。
预言1 bounty会降价:在看完该新闻 [根据 Node.js 官方公告 和 HackerOne 的相关报告 (2026年4月),Node.js 项目已暂停其安全漏洞赏金计划。] 后,Chrome不会降价吧。
应验:2026年5月1日 起,Google 官方对 Chrome 浏览器的漏洞奖励(Bug Bounty)结构进行了自 2010 年成立以来最大幅度的调整:基础奖励骤减:针对 Chrome 的普通内存安全漏洞,基础奖励金已降至 500 美元。一些安全研究人员指出,部分类别的奖励对比之前甚至缩水了 10 倍。停止特定奖金加成: 过去针对“任意读/写”等特定利用原语(Primitives)提供的额外奖金被取消。
预言2 人手都有0day:挖洞的成本越来越低,但挖洞实实在在烧token,对于不支付赏金的项目,人手都会有0day但不公开。
应验:2026年4月29日,国际安全研究团队Theori的研究员Taeyang Lee正式公开了代号为Copy Fail的Linux内核高危漏洞,官方编号CVE-2026-31431。2026年5月8日,由安全研究员 Hyunwoo Kim 发现并披露DirtyFrag,官方编号CVE-2026-43284/43500。这种史诗级漏洞,就这么突然被公开了。
预言3漏洞多到没地方收:N/A
应验:《荒诞!0day激增,Pwn2Own停止接收漏洞,部分落选者公开漏洞》 https://mp.weixin.qq.com/s/FGH1HjaghckKB_PBTX6rXQ 。
预言4安全漏洞研究将在2026.12.31结束:静待。。。