即日起本站进入Serveless时代!分享一些 hexo serveless 的经验。
最近发现本站的http服务总是不稳定,排查不出原因,怀疑是阿里云ECS的服务器只给10%的vcpu导致服务罢工,算了,炸了这个服务器,直接上CDN+对象存储吧。(还能省个机器钱。。。)
这个比喻我觉得很好,原先是购买了一套商品房,有很多用不到的东西,平时也得自己打扫。现在是向一楼老王买了一个客厅,向二楼老李买了一个卧室,物业帮忙建立一个通道,按需组合,由老王老李打扫。
整体设计
本站是hexo,是纯静态的,最佳实践应当是github.io提供的服务,但由于github.io在境外,访问非常不稳定,因此考虑部署在境内。
既然是纯静态的,能访问到静态资源就足够了,调研到现代的对象存储服务有一个卖点是“静态建站”,很适合我的场景。
其次,只挂对象存储,流量钱肯定比CDN的流量钱要贵,考虑到本站很多资源都是共享的,所以外层肯定要挂一层CDN。
此外,将静态存储公开出去,容易被恶意盗刷,而CDN本身拥有统计和防护,更适合作为外层服务,缓解对对象存储的攻击;而且CDN在SEO优化方面也比对象存储要好。
显然,我这么不专业的人都认为CDN+对象存储是最佳实践了,云服务商也考虑到了这种场景,因此CDN也提供了对接到对象存储的功能,可以说是很用心了。
对象存储服务
目前我的资源都在腾讯云和阿里云上,对象存储对应的产品叫腾讯云COS和阿里云OSS,由于后者有试用三个月的优惠,暂时就试用阿里云OSS。
阿里云OSS也有“一键建站”的新手教程,基本是上传个index.html和404.html,就能直接从外网访问了,没什么坑点。为支持网站类的对象存储服务,OSS还支持将 "/foo/" 配置为 "/foo/index.html" 的选项,将它开起来就能满足99%的场景了。
这部分主要工作量是将 hexo 生成的静态资源文件传到OSS的服务器上,API肯定是有的,然后找到一个轮子,一键部署到OSS上,体验很好:https://github.com/wertycn/hexo-deployer-ali-oss 。
该hexo插件的唯一缺点就是,暴力地上传所有文件,没有进行去重,恰好阿里云OSS提供对 Object 的 HEAD 功能,获取 Object 的基础信息,里面的 content-length 和 content-md5 对我们很有用,在上传前先校验远程文件和本地文件是否一致,从而跳过无意义的上传过程。
该缺点由我弥补,PR是:https://github.com/wertycn/hexo-deployer-ali-oss/pull/1 。
更令人开心的是,对资源进行 HEAD 请求是不计费的,可以放心地进行内容比对操作。
CDN
对象存储本身就是http访问,可以无缝作为回源站点,无论是腾讯云还是阿里云,都支持将对象存储设置为回源地址,非常契合我们的使用场景。
有些人错误地认为对象存储必须设置为public,不知道哪来的以讹传讹的观点。事实上,CDN可以使用AccessSecret来访问对象存储,如果CDN和对象存储是同一家云服务提供的,它甚至可以一键配置,连AccessSecret也不需要了。
唯一一个坑点,感觉是OSS设计上的一个缺陷:
- 对于无鉴权的OSS来说,访问
"/" 表示 GetObject("/")
- 对于有鉴权的OSS来说,访问
"/?accessSecret=xxxx" 表示 ListObject("/", accessSecret)
CDN也会有上述的行为,因此CDN配合有鉴权的OSS,首页会永久地无法访问,因为被视为了 ListObject 而非 GetObject。
修正:跟Silver大佬讨论后,大佬提出一条可行的路线(之前没尝试过)
方案:回源时不要使用 BUCKET.qcloud.com,而是使用静态网站功能提供的可能叫 WEBSITE.qcloud.com,且带上签名信息,腾讯云看起来是可以的,阿里云看起来不可。
本以为是腾讯云CDN+阿里云OSS才会触发的BUG,最后发现阿里云CDN+阿里云OSS也无法解决,官方明确告知CDN+OSS不支持对首页的访问,官方解决方案和我临时的解决方案也一样,对CDN的 "/" 进行 URL 重写。
https://help.aliyun.com/zh/oss/user-guide/why-am-i-unable-to-access-the-default-homepage-of-a-bucket-when-i-retrieve-an-object-from-a-private-bucket-by-using-cdn
CI/CD
上文描述,部署全靠手动,先执行 hexo g,再执行 hexo d 进行上传。
显然这是非常不优雅的行为,我无法容忍,由于本站是 github private repo,因此借助 github 的 CI/CD 会更优雅,毕竟。。。。
博客是这样的,写博客的人只要敲敲键盘就好了,而自动部署需要考虑的事情就很多了。——出自传奇二游《鸣潮》
在 _config.yml 里配置 deploy 需要如下信息,这些信息尤其是 accessKeySecret 肯定是不能提交到 github 仓库里的。
1
2
3
4
5
6
| deploy:
type: ali-oss
region: AAAAAAAAA
accessKeyId: ACCESS_KEY_ID
accessKeySecret: ACCESS_KEY_SECRET
bucket: BBBBBBBBBB
|
market上找不到合适的,自己写个workflow。恶心的地方在于将secret传到deploy plugin里面,研究了半天之后,认为hexo 的 _config.yml 不支持环境变量入参,只能 sed 替换文本了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| name: hexo upload oss
on:
push:
branches: [master]
jobs:
CICD:
runs-on: ubuntu-latest
steps:
- name: "Checkout"
uses: actions/checkout@v4
with:
submodules: "true"
- name: "Setup node"
uses: actions/setup-node@v4
- name: "Update Secret"
env:
ACCESS_KEY_ID: ${{secrets.ACCESSKEYID}}
ACCESS_KEY_SECRET: ${{secrets.ACCESSKEYSECRET}}
run: |
sed -i "s/ACCESS_KEY_ID/${ACCESS_KEY_ID}/" _config.yml
sed -i "s/ACCESS_KEY_SECRET/${ACCESS_KEY_SECRET}/" _config.yml
- name: "Deploy"
run: |
npm install hexo-cli -g
npm install
hexo g
hexo d
|
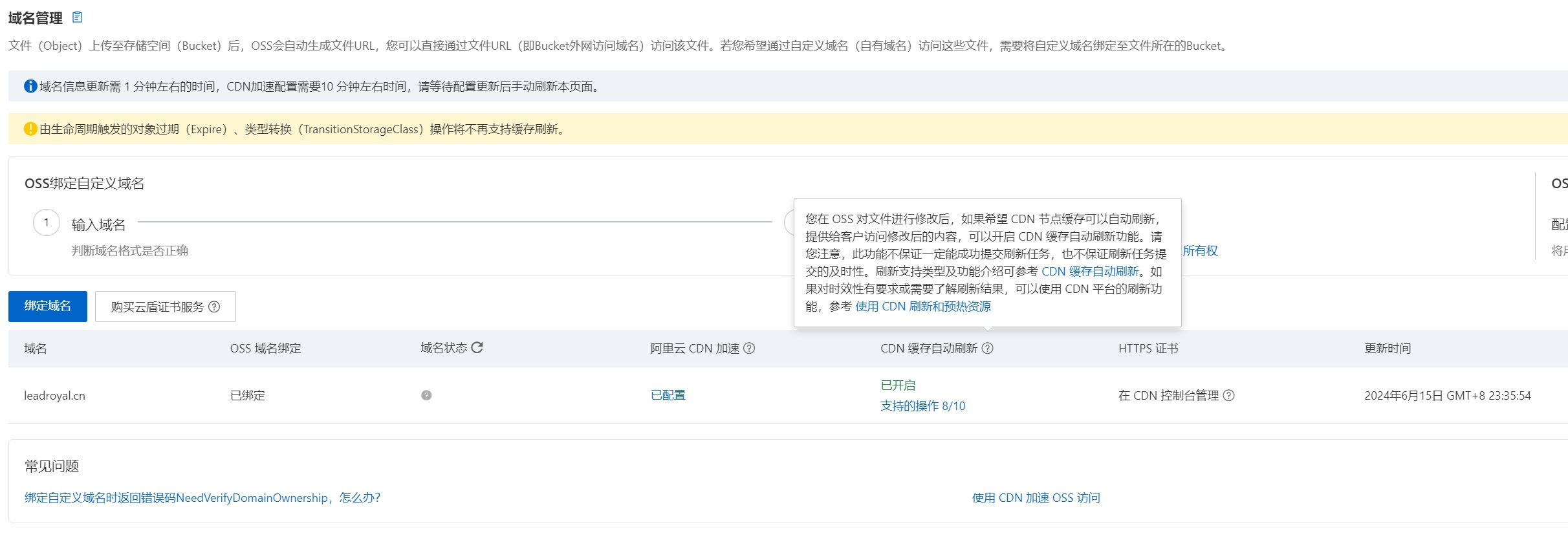
CDN刷新和预热
针对变更的页面,对CDN进行预热和刷新,一方面刷新内容,另一方面可以更大胆地对CDN的缓存策略进行配置。
刚刚发现当CDN和对象存储都是阿里云的时候,会有这个很人性化的功能,“当OSS有变动时自动刷新CDN”,阿里云牛逼!体验下来该功能极度好用,我直接CDN缓存设置为7天!
评论区的Serveless
由于Serveless,原先分配给nginx的django的评论功能也坏掉了,最终使用云函数和某个sql server作为backend。
重构前:
- 使用
https://domain/comment/* 来实现功能,包括发表评论、审核评论、展示评论等,是一系列restful接口,借助flask和sqlite实现,链接是:https://leadroyal.cn/p/1233 。
- CDN配置
/comment/* 下的所有内容都不进行缓存,从而保证评论区是最新的。
思考:
- 其实评论区的实时性要求也没那么高,使用CDN进行缓存也可以,
/comment/get/POST_ID 也可以做成静态的,只要评论区正常刷新即可
- 由于主站已经配置了CDN+OSS,CDN只能配置一个回源路径,不能让一部分URL回源A、另一部分URL回源B,不能直接将动态的部分分发给另一个后端。
- 方案1:评论区使用另一个域名,代价是再签一个ssl证书,在2024年之后,免费ssl证书的期限通常是3个月,很麻烦。所以可以考虑一个
domain 和 一个 www.domain,一个证书当两个用。
- 方案2(最终选择):直接使用云函数功能,阿里云叫函数计算FC,它拥有http触发器,省的自己去配了。代价是域名会比较丑陋,但也不是不能接受。
重构后:(有无数个方案,最终选择了一个普通的方案,凑合用,不算优雅)
- 提交评论,配置http触发器,将未审核评论追加到
/unreviewed/POST_ID.json
- 非要攻击的话,能把我的OSS写爆,但好像也没什么用,纯纯的脏数据罢了。
- 获取评论,配置http触发器,将已审核的评论和未审核的评论返回,由评论区的前端渲染。
- 审核评论,配置http触发器,需要口令,读取
/unreviewed/POST_ID.json,写入/reviewed/POST_ID.json。
- 审核邮箱提醒,配置定时触发器,读取
/unreviewed/POST_ID.json,发送到邮箱
函数计算有两种玩法,一种玩法是"Event函数",一种玩法是"Http函数",前者的入口是一个 message handler,后者的入口是纯http接口。对于我们这样的小项目,用哪个都无所谓,出于偷懒,我选择了 "Http函数"。
针对"Http函数",官方提供了一系列模板,例如 Springboot、django、flask、fastapi、webpy等等,经过一系列思想斗争和简单体验,最终选择是:
- django太重了
- springboot打包和部署不方便
- flask不错
- 由于官方给的flask的demo代码写得实在太好了,那就直接flask了
- fastapi不错
- webpy代码有点丑
代码不多,直接贴到这里吧。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
| import time
import json
from pathlib import Path
import oss2
from flask import Flask, request, jsonify, abort
BUCKET_NAME = "leadroyal-cn-comment"
INTERNAL_ENDPOINT = "oss-cn-hangzhou-internal.aliyuncs.com"
app = Flask(__name__)
app.config['JSON_AS_ASCII'] = False
def get_bucket() -> oss2.Bucket:
auth = oss2.StsAuth(request.headers["x-fc-access-key-id"],
request.headers["x-fc-access-key-secret"],
request.headers["x-fc-security-token"])
return oss2.Bucket(auth, "%s" % INTERNAL_ENDPOINT, BUCKET_NAME)
def to_path(post_id) -> (str, str):
return f"reviewed/{post_id}.json", f"unreviewed/{post_id}.json"
@app.route('/')
def hello_world():
return "Hello World!"
@app.route('/get/<int:post_id>', methods=["GET"])
def get(post_id: int):
try:
bucket = get_bucket()
reviewed_path, unreviewed_path = to_path(post_id)
merged = list()
for data in json.loads(bucket.get_object(reviewed_path).read()) \
if bucket.object_exists(reviewed_path) else list():
merged.append({
'author': data['author'],
'content': data['content'],
'time': time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(data['time'])),
})
for data in json.loads(bucket.get_object(unreviewed_path).read()) \
if bucket.object_exists(unreviewed_path) else list():
merged.append({
'author': "审核中",
'content': "审核中",
'time': time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(data['time'])),
})
return jsonify(merged)
except Exception as e:
abort(400, str(e))
@app.route('/put/<int:post_id>', methods=["POST"])
def put(post_id: int):
try:
data = request.json
author = str(data['author'])
email = str(data['email'])
content = str(data['content'])
ip = request.headers["x-forwarded-for"]
bucket = get_bucket()
_, unreviewed_path = to_path(post_id)
merged = list()
if bucket.object_exists(unreviewed_path):
merged.extend(json.loads(bucket.get_object(unreviewed_path).read()))
merged.append({
'author': author,
'content': content,
'email': email,
'time': int(time.time()),
'ip': ip
})
bucket.put_object(unreviewed_path, json.dumps(merged, ensure_ascii=False))
return "OK"
except Exception as e:
abort(400, str(e))
def check_token(args):
if not (token := args.get("token")):
raise PermissionError("No token" + token)
if token != '123':
raise PermissionError("Error token")
@app.route('/admin/', methods=["GET"])
def admin():
try:
check_token(request.args)
except PermissionError as e:
return str(e)
bucket = get_bucket()
merged = list()
for obj_info in oss2.ObjectIteratorV2(bucket, prefix='unreviewed/', delimiter='/', start_after='unreviewed/'):
if obj_info.is_prefix():
continue
for data in json.loads(bucket.get_object(obj_info.key).read()):
data['post_id'] = int(Path(obj_info.key).stem)
merged.append(data)
return jsonify(merged)
@app.route('/admin/accept/<int:post_id>/<int:comment_idx>', methods=["GET"])
def admin_accept(post_id, comment_idx):
check_token(request.args)
bucket = get_bucket()
reviewed_path, unreviewed_path = to_path(post_id)
unreviewed_lst = json.loads(bucket.get_object(unreviewed_path).read()) \
if bucket.object_exists(unreviewed_path) else list()
if not 0 <= comment_idx < len(unreviewed_lst):
return "Invalid comment_idx"
comment = unreviewed_lst.pop(comment_idx)
if unreviewed_lst:
bucket.put_object(unreviewed_path, json.dumps(unreviewed_lst, ensure_ascii=False))
else:
bucket.delete_object(unreviewed_path)
merged = json.loads(bucket.get_object(reviewed_path).read()) \
if bucket.object_exists(reviewed_path) else list()
merged.append(comment)
bucket.put_object(reviewed_path, json.dumps(merged, ensure_ascii=False))
return "OK"
@app.route('/admin/reject/<int:post_id>/<int:comment_idx>', methods=["GET"])
def admin_reject(post_id, comment_idx):
check_token(request.args)
bucket = get_bucket()
reviewed_path, unreviewed_path = to_path(post_id)
unreviewed_lst = json.loads(bucket.get_object(unreviewed_path).read()) \
if bucket.object_exists(unreviewed_path) else list()
if not 0 <= comment_idx < len(unreviewed_lst):
return "Invalid comment_idx"
_ = unreviewed_lst.pop(comment_idx)
if unreviewed_lst:
bucket.put_object(unreviewed_path, json.dumps(unreviewed_lst, ensure_ascii=False))
else:
bucket.delete_object(unreviewed_path)
return "OK"
if __name__ == "__main__":
app.run(host="0.0.0.0", port=9000)
|
优点:
- FC访问OSS属于内网访问,不要流量费
- 免运维,体验好,有日志
完工后,基本体验还行,有以下缺点:
- 由于我懒得绑定域名,目前用的是函数计算分配的随机域名,很长,但不对外,也不是不能接受
- 冷启动时,API耗时需要2000ms,对于评论区功能,也不是不能接受
- 热启动时,API耗时需要100ms,估计是OSS操作比较耗时
- 后端还好,前端跟shit一样,写起来极为痛苦,没想到2024年了js还是像以前一样shit
- 管理员页面在 /review.html 挂着,丑归丑,也不是不能用
好了,这就把旧的服务器炸掉,BOOM!